




前提
最近在 utools 上写了一个插件。
然后今天在 B站 捡到了一些好玩的(苏婆发丝特恰精),但是 UP主发的网盘链接为了躲避检测?进行了大量的添加。

刚好我做的插件就是相关的功能,于是准备对这串文字做点处理,达到自动提取出链接和提取码的功能。
插件细节不谈,今天谈谈本文的重点: 正则表达式
附 正则测试网站: https://regex101.com/
一、匹配 URL
(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]
这个正则刚发现的时候,一度被我认为是最牛的。但在后面的测试中,我发现匹配不了一些我想要的
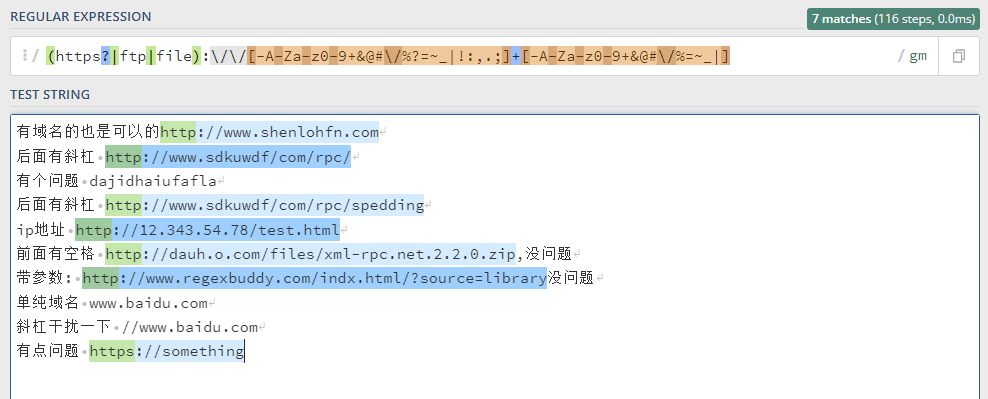
图中,无法单纯匹配域名,而且最后一个无效域名也被算进其中。
二、匹配域名
/[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\\.?/g
这个属于玄学范畴了
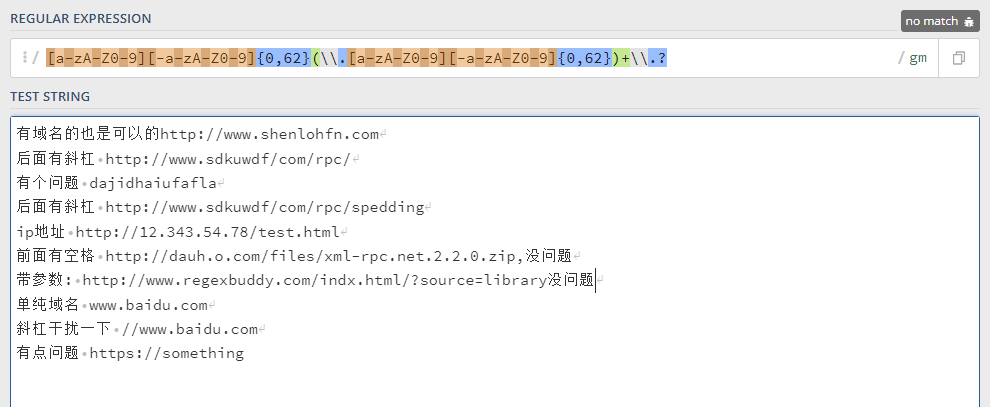
在插件中一直发挥了匹配域名的作用
但是现在,不管我怎么测试,都匹配不到了
三、全都匹配
为了达到我的目标:既能匹配域名,又能匹配
url,我决定在第一个的基础上修改一下,看能不能达到效果。
-
首先,去掉
http/https的必须性
((https?|ftp|file):\/\/)?[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]
这下只要是字母啥的都给你匹配上了
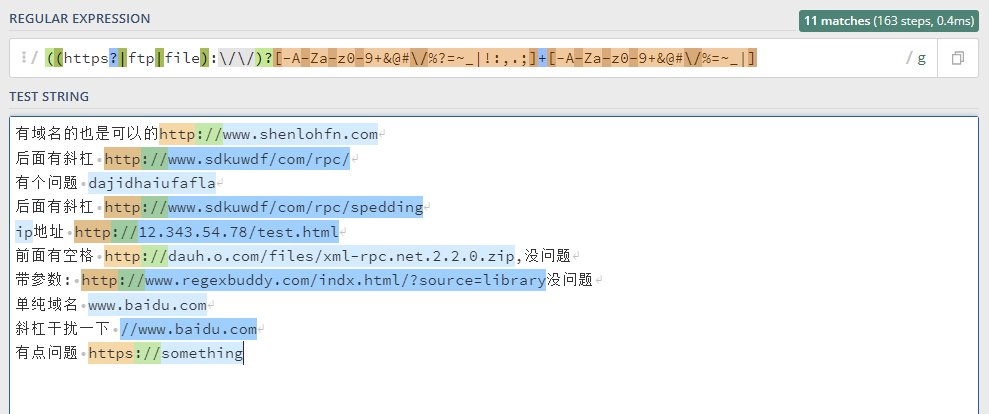
-
其次,要求在后面的域名匹配中至少有一个点
/((https?|ftp|file):\/\/)?(\.)+[-A-Za-z0-9+&@#\/%?=~_|!:,.;]+[-A-Za-z0-9+&@\/#%=~_|]/g
点是保证了,但是那个点挡住了最前面的匹配
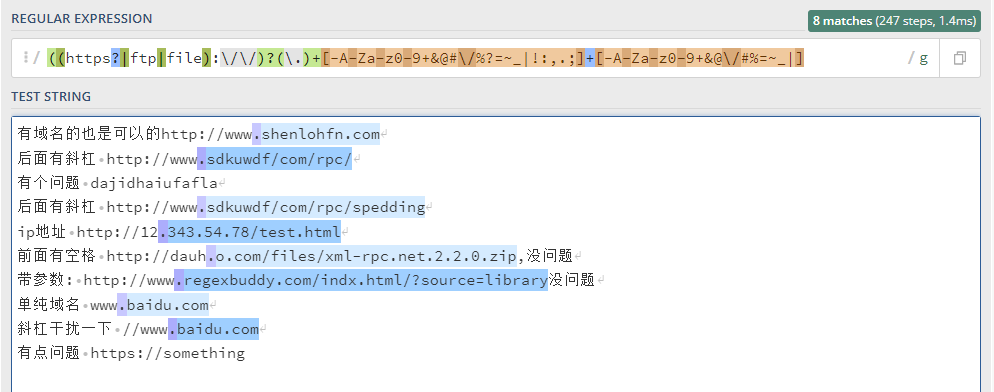
-
最后,根据域名的规则,在前面再加上一串就可以了
/((https?|ftp|file):\/\/)?[-a-zA-Z0-9]+(\.)+[-A-Za-z0-9+&@#\/%?=~_|!:,.;]+[-A-Za-z0-9+&@\/#%=~_|]/g
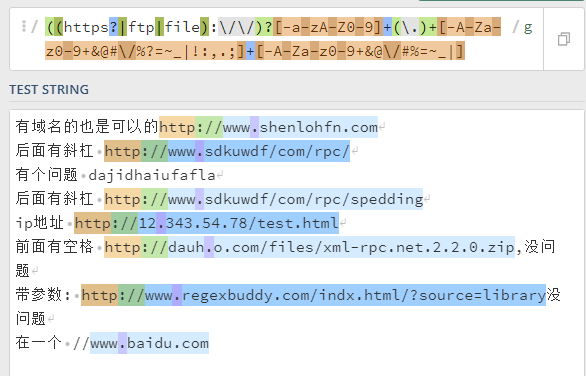
到此,一个我心目中完美的正则表达式就出来了。
四、回顾
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| . | 匹配除换行符 \n 之外的任何单字符。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。 |
| $ | 匹配输入字符串的结尾位置。 |
五、附录
有域名的也是可以的http://www.shenlohfn.com
后面有斜杠 http://www.sdkuwdf/com/rpc/
有个问题 dajidhaiufafla
后面有斜杠 http://www.sdkuwdf/com/rpc/spedding
ip地址 http://12.343.54.78/test.html
前面有空格 http://dauh.o.com/files/xml-rpc.net.2.2.0.zip,没问题
带参数: http://www.regexbuddy.com/indx.html/?source=library没问题
单纯域名 www.baidu.com
斜杠干扰一下 //www.baidu.com
有点问题 https://something
正则表达式匹配链接
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法