




准备工作
1.首先,目标是word中的内容,这就需要一个可以操作word的库了。百度一波,发现python-docx可以使用。
2.其次,要对陌生单词进行翻译,则需要调用翻译的接口。那就百度翻译吧!
3.最后将程序打包,给没有python环境的电脑用。
正式开始
1.安装python-docx
pip install python-docx
2.读取目标docx文件
from docx import Document
# 初始化一个文档,读取目标文件
doc = Document('word.docx')
# 进行数据操作
# code
# 保存文件
doc.save('word.docx')
3.查找有下划线的单词
# ...
# 遍历所有段落
for paragraph in doc.paragraphs:
# 在一个段落中遍历所有的样式
for style in paragraph.runs:
# 如果样式有下划线,说明该词是陌生的
if style.underline:
print(style.text)
4.调用百度翻译的接口
为了简化流程,就不去申请百度的翻译api了,直接用网页上的接口吧!
-
打开百度翻译的网页
-
打开控制台找到
Network
-
在框中输入要翻译的单词,就用happy吧
-
在
Network可以发现有很多xhr请求,经过对比和推敲,我们发现sug请求实现了翻译功能。下面来看看sug的请求方式:
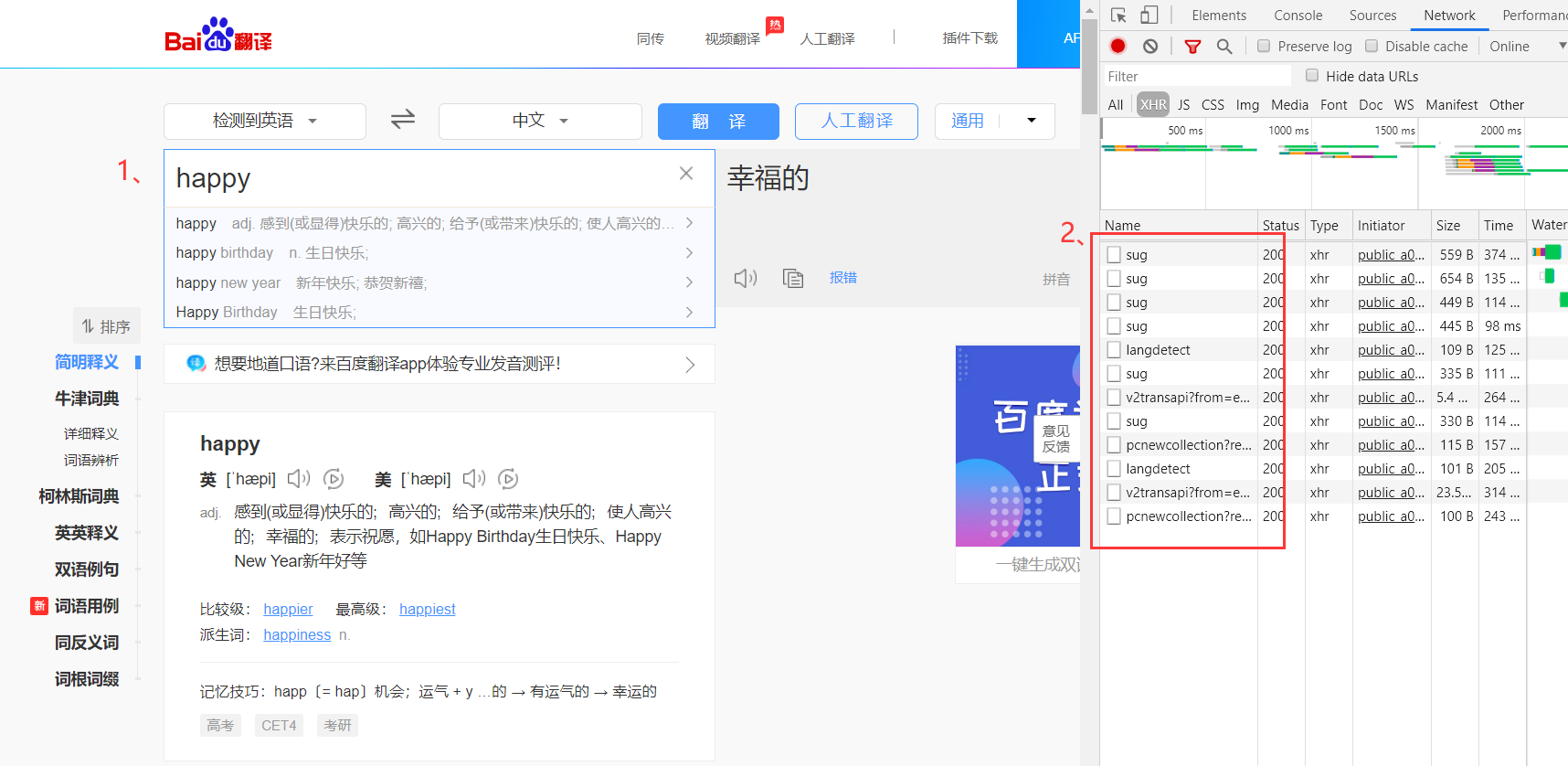
请求连接为http://fanyi.baidu.com/sug
请求方式为POST
再看一下携带的数据
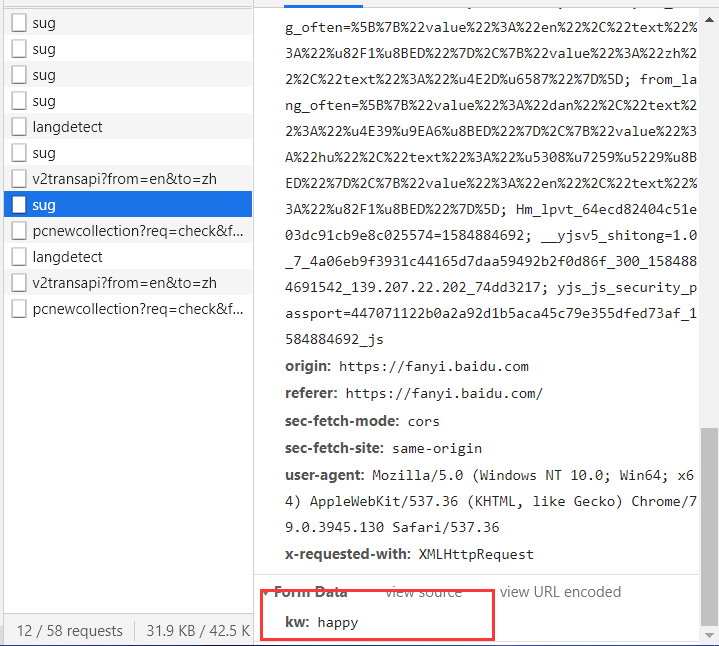
仅仅只有一个参数,也就是我们要进行翻译的单词。 -
开始写代码
# 定义一个翻译的函数
def translate(word):
url = 'http://fanyi.baidu.com/sug'
data = {
'kw': word
}
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'http://fanyi.baidu.com/'
}
res = requests.post(url, data=data, headers=headers)
# 拿到返回的数据后,提取我们需要的数据
data = res.json()['data']
mean = data[0]['v']
return mean
5.整合
各个小部分的功能都做好了,现在就整合在一起了。
一些小细节问题
1、当需要翻译的单词非原型的时候,可能无法进行翻译。因为该请求没有翻译的数据。
2、为了避免频繁请求而被限制,添加时间间隔。
3、为了让某人更简单的操作,一键直接获取当前目录的所有docx文件并进行翻译。
from docx import Document
import requests
from time import sleep
from random import randint
import os
def translate(word):
url = 'https://fanyi.baidu.com/sug'
datas = {
'kw': word
}
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'http://fanyi.baidu.com/'
}
try:
res = requests.post(url, data=datas, headers=headers)
mid = res.json()['data']
# 若果获取的数据为空,说明该词非原型
if not mid:
res = requests.post(url, data={
'kw': word[:-1] # 去掉复数s
}, headers=headers)
mid = res.json()['data']
key = mid[0]['k']
mean = mid[0]['v']
return mean
except:
print('↑ 该词可能非原型,暂不支持翻译')
return ' '
def docx_(path):
cnt = 0
doc = Document(path)
for paragraph in doc.paragraphs:
for style in paragraph.runs:
if style.underline:
if cnt % 10 == 0:
sleep(randint(3, 6))
print(style.text)
res = translate(style.text.strip())
cnt += 1
style.text += '( ' + res + ')'
doc.save(path)
if __name__ == '__main__':
print('仅支持docx文件')
for f in os.listdir(os.getcwd()):
if '.docx' in f:
print(f)
try:
docx_(f)
input('翻译完成,请打开文档查看!')
except:
input('文件错误!')
else:
input('没有word文档')
6.补充
os.listdir()列出当前路径下的所有文件os.getcwd()获取当前路径
7.打包
打开命令行窗口,输入命令pyinstaller -F -i test.ico word.py
总结
使用了python-docx的库,完成了对文档的翻译。总体上可以,但存在一些不足。一是写代码的效率低下,二是阅读开发文档不够精准有效。
? 为什么不支持doc格式的文档
docx是开放格式。他本质上是一个zip文件,你可以用解压缩软件把它解压缩成一个目录的,下面包括好几个目录,内置图片什么都在相应的目录下。而正文内容则是用XML去存储的,所以要用python去解析是相对容易的。
doc是早一代的文件,是封闭的,一般类似openoffice或者wps这种同类软件会去反破译格式然后支持,而且也不能保证完美支持。这个难度的确比docx要高许多的。
copy自知乎
记一次python翻译文档
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法